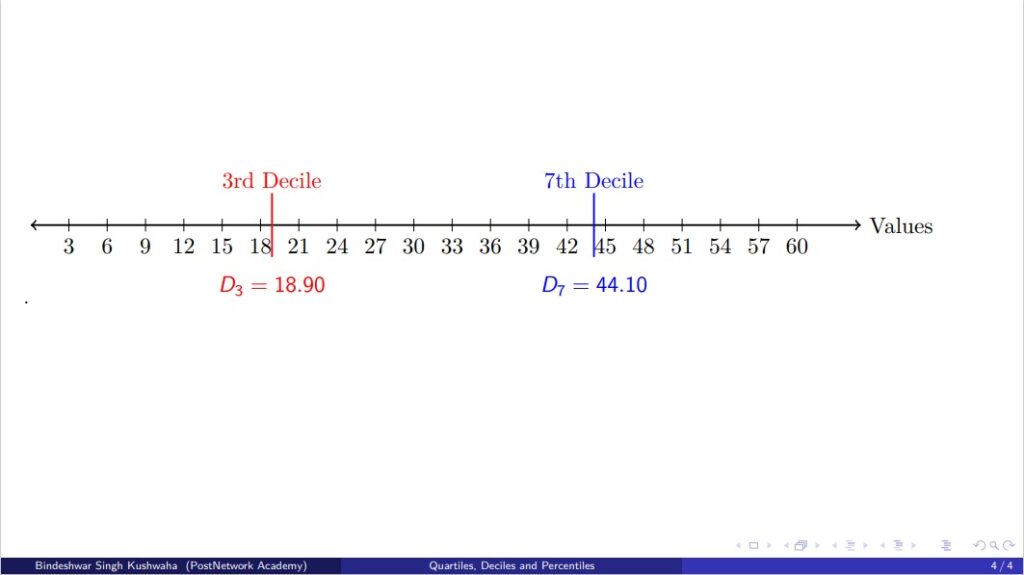
Gradient of Softmax + Cross-Entropy w.r.t Logits
Gradient of Softmax + Cross-Entropy w.r.t Logits Author: Bindeshwar Singh Kushwaha – PostNetwork Academy Goal We want to compute: $$ \frac{\partial L}{\partial z_j} $$ Notation: Logits: \(z = [z_1, z_2, \dots, z_C]\) Softmax: \(\hat{y}_i = \frac{e^{z_i}}{\sum_{k=1}^{C} e^{z_k}}\) Cross-Entropy Loss: \(L = -\sum_{i=1}^{C} y_i \log \hat{y}_i\), where \(y_i\) is one-hot. [Insert Neural Network Diagram Here] Loss […]
Gradient of Softmax + Cross-Entropy w.r.t Logits Read More »