
K-Nearest Neighbors algorithm (KNN)
K-Nearest Neighbors algorithm (KNN) is a very important supervised machine learning algorithm and one should start from this algorithm. It is easy to understand compare to other algorithms and does not involve complex mathematical concepts.
In this post, I will explain k-Nearest Neighbors algorithm using Irish flowers data set.

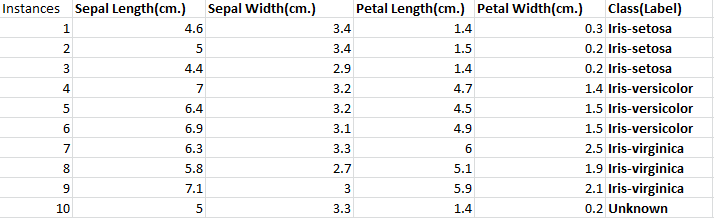
From the above two, one figure and table you can understand Irish dataset which has four features sepal length, sepal width, petal length and petal width.
Iris-Flowers Dataset
In original dataset there are 150 instances which has four features sepal length, sepal width, petal length and petal width and three features Iris-setosa, Iris-versicolor and Irish-virginica. For the sake of simplicity, I have only take only ten instances in which nine are labeled and one is not labeled. Nine instances will be used for training and one will be used for testing.
Working of K-Nearest Neighbors Algorithm
From the data set you can see nine instances having labels and the tenth has not a label. To train the model, distance will be calculated from 10 instance to all instances, and the value of k should be chosen.

If we take k=3, you see the minimum three distances are 0.424 (Iris-Setosa), 0.141(Iris-Setosa) and again 0.721(Iris-Setosa). So, if k=3 majority of Iris-Setosa instances are nearest to instance number ten.
So, instance 10 will have label Iris-Setosa because 3 Iris-Setosa instances are nearest to instance number 10.
Python’s Code for K-Nearest Neighbors Algorithm
from sklearn.neighbors import KNeighborsClassifier
i1=[4.6,3.4,1.4,0.3]
i2=[5,3.4,1.5,0.2]
i3=[4.4,2.9,1.4,0.2]
i4=[7,3.2,4.7,1.4]
i5=[6.4,3.2,4.5,1.5]
i6=[6.9,3.1,4.9,1.5]
i7=[6.3,3.3,6,2.5]
i8=[5.8,2.7,5.1,1.9]
i9=[7.1,3,5.9,2.1]
X_train=[i1,i2,i3, i4,i5,i6, i7,i8,i9]
irst, irver,irvirg ="Iris-setosa", "Iris-versicolor", "Iris-virginica"
y_train=[irst,irst ,irst ,irver , irver,irver,irvirg,irvirg,irvirg]
modal= KNeighborsClassifier(n_neighbors =3, p=2)
modal.fit(X_train, y_train)
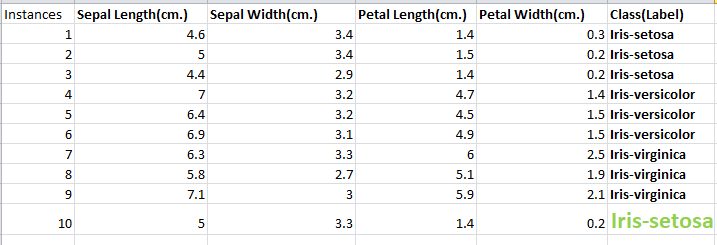
X_pred=[[5,3.3,1.4,0.2]]
Unknown= modal.predict(X_pred)
print("Predicted=",Unknown)
In the above code from
sklearn.neighbors import KNeighborsClassifier imports KNeighborsClassifier class which is used to create instance of KNN model. Nine lists i1,i2,…,i9 are created which are instances without labels.
Therefore, X_train nested list is created which is basically a table having all features except tenth. Furthermore, y_train has all labels corresponding to X_train instances. KNeighborsClassifier(n_neighbors =3, p=2) means number of neighbors are 3 and p=2 means Euclidean distance if the value of p=1 it is manhattan distance.
Furthermore, fit() function takes two arguments X_train, y_train and it will train the model. predict() function will predict the label. Finally, print function will print the label.